
You have FHIR data arriving from a provider API, Postgres is already running and you know JSONB is genuinely fast. And in fact, it’s working fine in staging - so why not just store it there?
The logic seems completely airtight. You do not need new infrastructure, new skills, or new vendor contracts. Just dump the JSON blob into a JSONB column and query it when you need it.
This exact thought crosses the mind of almost every health-tech developer building against a FHIR API for the first time. And almost every one of them eventually hits the same wall.
It won’t be obvious at first. Ingestion goes smoothly and the first queries return exactly what you expect, but real pain shows up later as data grows and queries get complex.
This post is about where standard SQL stops being enough for FHIR data and what actually works instead.
What FHIR Data Actually Looks Like?
Fast Healthcare Interoperability Resources (FHIR) is a standard for representing clinical data as structured JSON objects called resources. That definition sounds simple, but the reality is complex.
A single patient in a real-world health system is never just one record. It is a web of linked resources:
- Observations (lab results, vitals),
- Conditions (diagnoses),
- MedicationRequests (prescriptions),
- Encounters (visits),
- Practitioners (doctors),
- Organizations (hospitals and clinics).
Each resource can reference any other resource by ID, and fields inside a resource are frequently nested five or six levels deep. And because FHIR allows providers to add custom extension fields, two Observations from two different health systems can look structurally different even when they describe the same lab test.
Instead of treating it like a standard JSON document, think of it as a filing cabinet where every folder contains references to three other folders, and some of those folders only exist at specific hospitals. The standard defines the cabinet, but each institution decides what goes inside.
This is not regular JSON, but rather a complex graph with a schema that evolves per institution.
FHIR Resource Graph
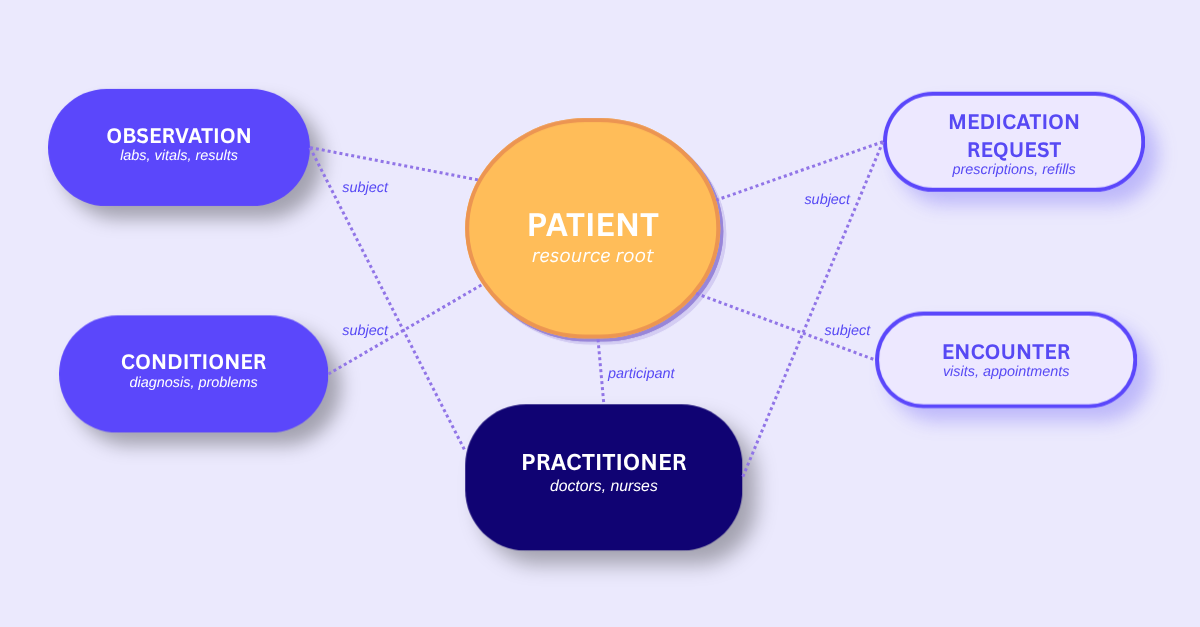
FHIR Patient is the root of a reference graph. Pulling one record means resolving a web of linked IDs.
Why JSONB Feels Like the Right Answer?
To be fair, Postgres JSONB is a remarkably powerful tool that natively supports GIN indexes, advanced path operators and partial updates without forcing you through a painful, risky schema migration every single week. It handles minor version updates smoothly, so when a new FHIR iteration rolls out, it won’t break your existing database columns or force you to sketch out risky backup plans.
That inherent flexibility makes day one feel like a win. Your inbound pipelines run smoothly, initial queries load fast, and you’re on time. But the real problems don’t show up until you’re trying to actually use all that accumulated clinical data.
The pressure to go this route is also real. Proposing a purpose-built clinical data store to a team that already has a healthy Postgres instance running sounds like over-engineering. It’s tempting to stick with “Just use JSONB” until the downstream performance pain actually becomes visible in your application logs.
Three Reasons SQL Falls Apart with FHIR
1. FHIR is a graph, not a document
A standard query like “give me all active medications for this patient” requires heavy relational mapping. In the FHIR world, that simple request forces you to chase a multi-directional trail.
If a doctor writes a portal refill, your database must resolve a path like this:
Patient → MedicationRequest → Medication → Organisation.
However, if that exact same prescription is tied to a specific hospital visit, the clinical graph branches completely differently. Your query must now traverse:
Patient → Encounter → MedicationRequest → Medication → Organization.
Each of those steps lives in its own resource, which usually translates to separate rows and distinct JSONB blobs in your database.
In a relational database, you are writing a recursive JOIN across JSONB columns. That is not a SQL query; it is a graph traversal written in SQL. It is slow, it is brittle, and it breaks every time the reference chain changes.
Performance hits you as you scale. While manageable for a few hundred patients, those serial JSONB lookups start saturating your connection pool once you’re handling tens of thousands across different networks.
Eventually, you find yourself aggressively caching, pre-computing results in background jobs or reading replicas just to keep things running. All of that is engineering time spent working around the underlying wrong data model.
2. The nesting goes deeper than you expect
A blood pressure reading is not a single value. It is a nested structure with components, each carrying its own codings, reference ranges, and interpretation blocks.
To extract the systolic reading, your JSONB path query looks something like:
resource → ‘component’ → 0 → ‘valueQuantity’ → ‘value’
This assumes you know exactly where that index sits. But two hospitals rarely organize components the same way. Add in custom extension fields, and your query’s reliability drops to near zero across your data sources.
The FHIR Observation resource specification alone has over 30 optional fields. Real-world data is inconsistent, as one hospital can include an interpretation block while another can bury that same data in an extension. Your carefully crafted JSONB path string usually only works for the one institution it was written for.
3. You will have to backfill
The shortcut is tempting: extract only the fields you need now into dedicated columns. It’s clean and fast, until six months later when you need a new product feature field.
Now you’re running migrations across potentially millions of archived FHIR records, re-parsing JSON that might have changed format. If you’re ingesting data from multiple providers, you’re doing this per schema variant. Provider A calls it ‘valueQuantity’; Provider B uses an extension; Provider C is on FHIR R5 and the field has moved. One migration becomes three.
The backfill trap isn’t a one-time cost. Every new feature reopens the question of which fields are “enough,” and the answer keeps changing as your product grows.
Getting Patient Medications: JSONB vs CDR
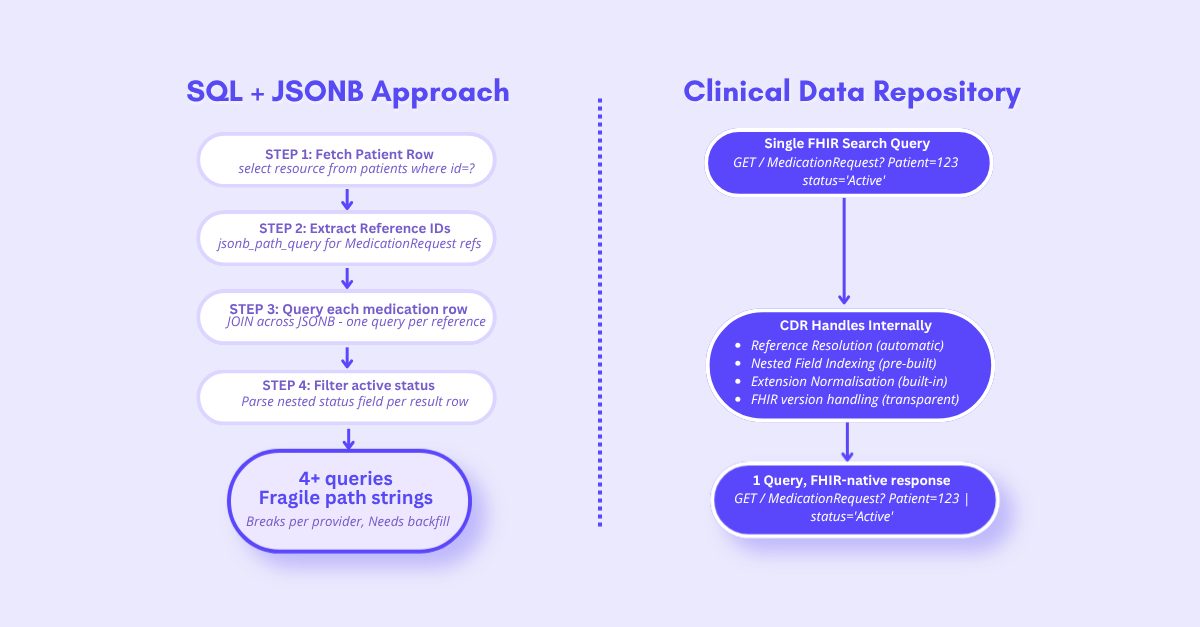
Both return the same data. One is sustainable.
You Will Build a CDR Anyway
Here is what usually happens. You store FHIR as raw JSONB. Queries get complex, so you write an extraction job. That helps, until you need to resolve references, so you build a reference resolver. Then someone asks for a search feature, so you add a custom indexing layer. Then the indexing layer needs a consistent interface, so you add a query abstraction.
Congratulations!! You have spent three months building a worse version of something that already exists.
This is not a hypothetical edge case. It is the predictable outcome that almost every team working with FHIR data eventually reaches. In fact, customers will end up building a poor man’s version of a CDR anyway.
The Accidental CDR: How It Happens?
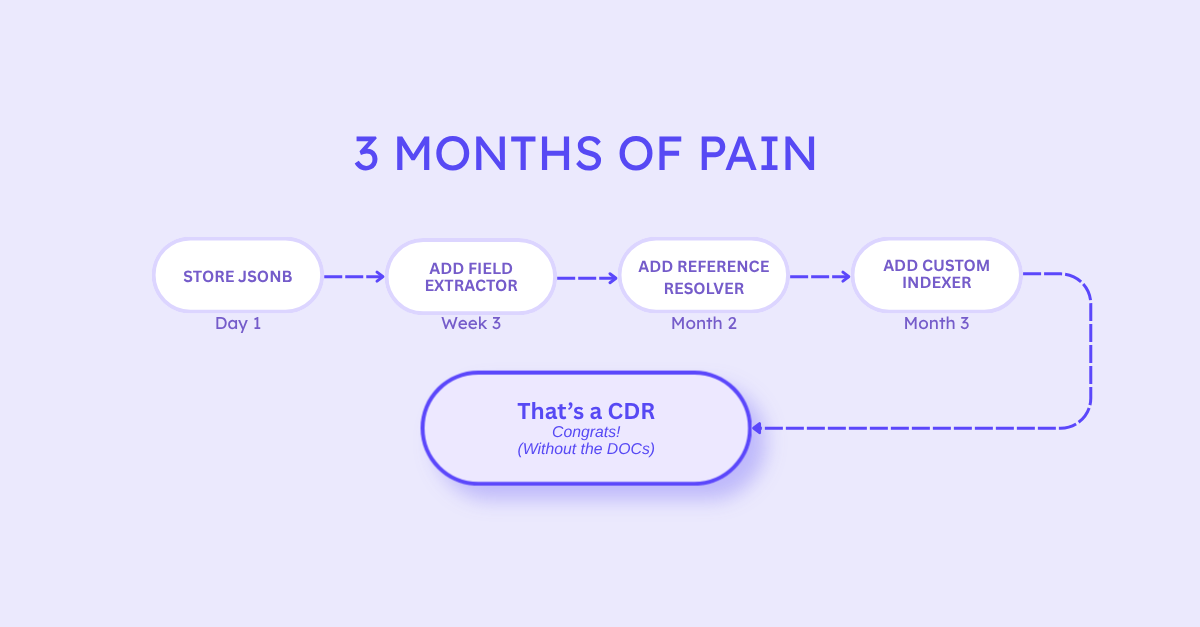
The path from “just store it in JSONB” to “we built a CDR” takes about one quarter. Except that the CDR you built has no community, no documentation, and no one else maintaining it.
What a Clinical Data Repository Actually Does
A Clinical Data Repository (CDR) is purpose-built storage for FHIR data that handles these headaches natively:
- Automatic indexing: It handles nested fields out of the box. No JSONB path queries or GIN index maintenance required. You search by FHIR parameter, and the CDR knows where to look.
- Built-in reference resolution: Query for a patient’s medications, and the CDR resolves the Patient → MedicationRequest references on read. You get one response, not a web of lookups.
- Schema-free versioning: FHIR R4 and R5 resources can coexist easily. Provider-specific extensions are stored and queryable without schema changes.
- FHIR-native search API: Query using standard FHIR search parameters instead of writing custom SQL. This interface remains consistent regardless of which CDR you use, which brings us to one of its biggest advantages - ’Portability.’
The portability point is a huge win here. CDRs share a consistent query language, much like SQL is the same language whether it runs on Postgres, MySQL, or SQLite. Switching from AWS HealthLake to Medplum doesn’t mean rewriting your logic - it’s just updating a base URL.
You also get compliance features like audit logging and access controls out of the box, rather than bolting them on when a HIPAA audit arrives. It is just not usually on the roadmap until it suddenly becomes urgent.
CDR Options and How They Compare
The CDR market has matured significantly. These are production-tested systems used at enterprise scale.
| CDR | Deployment | Open Source | FHIR Support | Best For |
| Google Healthcare API | Managed | No | R4, STU3,DSTU2 | Large-scale clinical data analytics natively on GCP |
| Azure Health Data Services | Managed | No | R4 | EHR data integration and enterprise ML workflows in Azure |
| Smile Digital Health | Managed and Self-hosted | No | R4, R5, STU3, DSTU2 | Multi-version FHIR compliance and cross-platform data fabrics |
All three support the standard FHIR search API, so your query logic stays consistent regardless of the underlying server.
Making the Right Architectural Call
Choosing the right storage architecture comes down to how your application interacts with healthcare records over its entire lifecycle.
Not every use case needs a CDR. If you’re building a pure data pipeline where FHIR records pass through and aren’t queried, or you’re storing archival logs, S3 or a simple JSONB column is perfectly reasonable. The same goes for archival storage and audit logs, where you only ever need to retrieve a specific record by its exact ID, not search or traverse it.
The rule of thumb:** If you’ll ever need to query, filter, or traverse FHIR data after you* store it, use a CDR. If you truly just need to store it and never touch it again, S3 or SQL is fine.*
The expensive mistake is choosing simple storage for something that starts as archival but quietly becomes a query engine six months later. Build for the future, not just today.
Bottom Line
If there is a common theme running through all of this, it is that managing complex clinical data infrastructure comes with a spectrum of heavy technical trade-offs. As standards evolve and real-world implementation improves, we’re finally moving toward a future where accessing health records is as simple as integrating banking APIs.
At Fasten Health, we’re committed to simplifying this infrastructure and unlocking the true potential benefits of modern healthcare interoperability. Our platform,Fasten Connect, provides a secure, single integration boundary to over 70,000 healthcare systems nationwide to easily feed your dedicated CDR.
If you are not sure which CDR fits your stack, or your integration is getting stuck at the storage layer, let’s talk through it. Schedule a 30-minute chat.
Not sure who is legally required to give you FHIR data access in the first place? Start with our earlier post in this series: Who’s Actually Required to Provide Access to Clinical Data?
 Fasten’s 𝐁𝐫𝐢𝐧𝐠 𝐘𝐨𝐮𝐫 𝐎𝐰𝐧 𝐈𝐝𝐞𝐧𝐭𝐢𝐭𝐲 capability is now live
Fasten’s 𝐁𝐫𝐢𝐧𝐠 𝐘𝐨𝐮𝐫 𝐎𝐰𝐧 𝐈𝐝𝐞𝐧𝐭𝐢𝐭𝐲 capability is now live